




PSYCHOMETRICS: What is the difference between disproportionate and proportionate stratified random sampling?
In stratified random sampling, you divide the population in sub-populations, or strata. Disproportionate stratified random sampling refers to when you take an equal-sized random sample from each strata. Proportionate stratified random sampling refers to taking samples where the size of the sample is proportionate to the size of the strata. If you are very concerned about giving a voice to everyone, you should use disproportionate SRS. However, if you would like to make accurate predictions, it is best to use proportionate SRS.
PSYCHOMETRICS: What is a Guttman scale?
A Guttman scale is a scale in which agreeing with an extreme statement indicates agreement with milder, related statements. If a respondent agrees with an extreme statement, such as “I love everything about pencils”, it can be assumed that the respondent would also agree to statements such as “I like pencil lead”, “I like pencil erasers”, etc. (weird example, but you get the gist). Due to these assumptions, more items can be answered in less time.
PSYCHOMETRICS: What are the assumptions of classical test theory? (Hint: there are four)
The assumptions of Classical Test Theory are that 1. Measurements errors are random, 2. Mean error of the measurement is zero, 3. True scores and errors are uncorrelated, and 4. Errors on different tests are uncorrelated. Some of these assumptions are problematic, however. For example, the assumption that true scores and errors are uncorrelated. This may be problematic because we are probably better at getting average than extreme outliers.
PSYCHOMETRICS: In the equation X = T + e, what do the various components mean. Explain your answer, don’t just give me the name of the term.
This is true score theory. X represents the observed score, T represents the true score, and e represents the measurement error. The equations means that the observed score is a function of the true score plus the measurement error. However, we can never truly know what a person’s “true” score is- it is theoretical. This could only be found by having someone take a test an infinite number of times and then averaging those scores. Measurement error is anything other than your true score that contributes to your observed score. We assume these are random and normally distributed.
PSYCHOMETRICS: When and why do we use the Spearman-Brown correction?
We use the Spearman-Brown correction when we are doing split-half to check for internal consistency. Because we are dividing the test into two halves and calculating a reliability score for each half, our half test reliability will be off from the full test reliability and the prediction will not be fully accurate. The Spearman-Brown formula corrects for this and raises our half test reliability.
PSYCHOMETRICS: Explain item difficulty and item discrimination in classical test theory.
Item difficulty describes at what difficulty level the items of a test are written, which can be measured by how many respondents are getting the item correct/incorrect. You want to make sure you pay attention to item difficulty, in order to make sure you still have item discrimination. Item discrimination means that you can identify respondents based on who scored high, low, medium, etc. Therefore, if items are too difficult and everyone is failing, you have low discrimination and you cannot differentiate between respondents. Likewise, if items are too easy and everyone is passing, you still get low discrimination.
PSYCHOMETRICS: Compare and contrast predictive and concurrent validity.
Concurrent and predictive validity are both types of criterion-related validity.
Concurrent validity measures whether a score on some particular test is related to a criterion measure taken at the same time. For example: current employees take a test and then those scores are correlated with a performance measure at the same point in time.
Predictive validity measures whether a score on some test is related to the criterion measure taken in the future. For example: a graduate student’s GRE score predicts that student will do well in the future, and later performance measured to see if he/she actually did well.
PSYCHOMETRICS: Explain what is meant by incremental validity.
Incremental validity means that adding additional predictors can explain more about the criterion measure and fill in gaps that the current predictors are missing. Basically, the more predictors that you have, the more you can theoretically increase your validity. For example, if I am measuring potential success in graduate school with just the GRE, my predictions might be “okay”. However, if I use GRE, GPA, personal statement, and letters of recommendation, I may be increasing validity.
PSYCHOMETRICS: Explain what the adjusted true score estimate is and how and why it will differ from the observed score? What three factors affect the discrepancy between the observed score and the adjusted true score estimate? Explain why/how those factors affect that discrepancy.
The adjusted true score estimate essentially describes the revision of your estimated true score.
So you have X1, which is your observed test score. Then you have information on the mean and the reliability of the test. Using these three pieces of information, you can find your adjusted estimate of your true score. The estimated true score= mean+reliability(X1-mean). For example, say I received a 20 on the test. The mean is 16 and the reliability is 0.8. Therefore, my adjusted true score estimate is 16+.8(20-16), which comes out to be 19.2.
The three factors that affect the discrepancy between the observed score and the adjusted true score estimate are the test reliability, the size of the difference between the observed score and the mean, and the direction of the difference between the observed score and the mean.
As test reliability decreases, the discrepancy between the observed score and the estimate will increase. As the size of the difference between the observed sore and the mean increases, or the extremeness of the score, the discrepancy between observed score and estimates will also increase. Finally, the direction of the difference between the observed score and the mean also effects the discrepancy because the scores tend to regress toward the mean. Therefore, if an observed score is above the mean, the estimate will likely be lower than the observed. If the observed score is below the mean, the estimate will likely be higher than the observed score.
PSYCHOMETRICS:
Item 1 has an item difficulty level of 0.43, which indicates that 43% of respondents got the item correct. This difficulty level is good, because the ideal level of difficulty is around a 0.5. This item indicates a “moderate” difficulty level.
However, the item discrimination level of -.05 is not only low, but is also negative which is a bad thing. More “low” performers on the exam, or people who scored low on the overall test, got this item correct (14 people) than the “high” performers, or people who scored well on the overall test, did (9 people). Clearly, there is something wrong with this item and it should be removed. It could be that there is something confusing or misleading about the item.
Item 2 has an item difficulty level of 0.61, which indicates that 61% of respondents got the item correct. This is can be considered an “somewhat easy” difficulty level. More people are getting the item correct than wrong, which can be acceptable depending on the purpose of the test. For a Psych 101 test, this is fine.
The item discrimination of 0.17 is okay. Very few (2 out of 27) high performers got this item wrong, whereas most of the low performers (19 out of 27) got this item wrong. This shows that the item does indeed help to discriminate between high and low performers on the exam and therefore should remain on the exam. However, two of the alternatives (B and D) were not selected by anyone out of the 54 respondents. This item should still be examined to see if these two alternatives can be edited so that they seem more likely to be correct and are not as useless in this item.

JA/PA: Research indicates that systems using ____ are judged to be less effective at developing employees.
Forced distribution
JA/PA: Research suggests that supportive coaching can be positively related to perceptions of leader effectiveness. Supportive coaching may also help improve ____, which directly facilitates learning and individual development.
Self-efficacy
JA/PA: A PMS that seeks to recognize contributions from all employees without elevating some above others is known as a:
parity-based system
JA/PA: Legislators who are interested in pushing public schools toward a system whereby teacher pay is based on how successful their students perform on standardized tests, often are pushing for this sort of PMS:
merit-based system
JA/PA: Deliberate rating distortion is more prevalent than unintentional rater error
True
JA/PA: A PMS with a pay for performance plan that seeks to link reward to individual performance might include
merit pay or skill-based pay
JA/PA:A PMS with a pay for performance plan that seeks to link reward to organizational performance might include
profit sharing or stock ownership
JA/PA: True or false, Companies most often use a hybrid of a graphic rating scale and a BARS
True
JA/PA: Using a weighting algorithm to weight performance dimensions that sum to an overall performance score
Would add administrative burden and not be at all practical across many positions
JA/PA: A main reason to consider practice issues of organizational culture and business needs when implementing a PMS is that-
Emphasizing psychometric soundness alone will lead to failure
JA/PA: to be effective, a PMS should include
A well articulated set of performance dimensions, behaviorally-anchored continuum of effectiveness, a structured process for communicating performance feedback
JA/PA: Performance management dimensions, as contrasted with performance measurement tend to be:
Broader in scope and explicitly tie business strategy to individual performance
JA/PA: What does it mean to consider “cascading goals” when implementing PMS?
Consider organizational level performance goals, to departmental level performance goals, to individual level performance goals
JA/PA: Which is NOT one of the recommended ways to ensure proper use of a performance management system
Make it optional, allowing employees to opt-in or out of various parts of the system
JA/PA: Which of the following can be used on a regular basis to evaluate performance management in an organization?
All of the above: Distribution of performance ratings, overall satisfaction with the performance management system, and unit level performance
Motivation: Cognitive Evaluation Theory (CET) states _____________
presenting a reward for someone who is performing an interesting activity can reduce interest in the activity. Why? When we evaluate a task, we look for how well it will make us feel in-control and competent. The presentation of a reward compromises a person’s self-determination and competence. In terms of reward-giving, self-determination is especially at-risk.
Motivation: Self-determination...
presenting a reward for someone who is performing an interesting activity can reduce interest in the activity. Why? When we evaluate a task, we look for how well it will make us feel in-control and competent. The presentation of a reward compromises a person’s self-determination and competence. In terms of reward-giving, self-determination is especially at-risk.
Motivation: Equity theory
Write the Equity Theory formula. Use an example. Include numerical values.
P1 (outcomes/inputs) = P2 (outcomes/inputs)
The relationship between outcomes and inputs has to be the same between Person 1 and Person 2 for there to be perceived equity.
Motivation: define planning fallacy
Planning fallacy occurs when we are familiar with a task and complete that task often. In these situations, we often underestimate the amount of time that it takes for us to complete these tasks, and therefore plan poorly.
Motivation: define org culture
Organizational culture does not have one definition, but instead is made up of many components. These components commonly include things such as organizational norms, values, branding, symbols, environment, traditions, dress code, language, and behaviors. Organizational culture is considered “strong” when employee identify strongly with the organization and adopt the norms.
Motivation: When are attitudes related to behaviors?
Stable, strong, specific, and low-press environments (environments w/o strong norms that sway you)
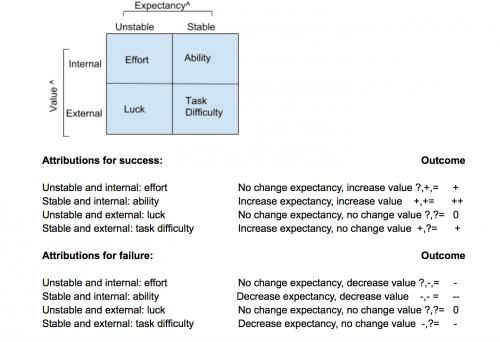
Motivation: Weiner's model (attributions for success and failure)
Stats (1): Some things about α (alpha)
-it is the rate of obtaining false positive
-increasing alpha increases power
-we typically set alpha as part of study design
Stats (1): as our sample size gets larger, our standard error of the mean gets...
smaller
Stats (1): definition of null distribution
the distribution we would expect if the null hypothesis were true
Stats (1): Probabilty I'll select a blue OR a yellow marble
use addition (2/10 + 5/10 = 7/10)
Stats (1): What is the probability that I will randomly select a male psychology student? (male AND psychology)
use multiplication (5/10 x 4x10)
Stats (1): if we wanted to minimize type 2 errors, we would do what to alpha?
High alpha
Stats (1): Sleep deprivation will reduce the ability to perform a complex tasks... this is one-tailed or two-tailed?
one-tailed
Stats (1): If several high/extreme scores were inserted at the right end of a normal distribution, which order of mean, median, and mode would you expect to find (write them largest to smallest)
Mean>median>mode
Stats (1): What is a limitation of null hypothesis significance testing?
It does not denote practical importance.
Stats (1): What is the z-score formula?
X̄ - mean / sd = z score
Stats (1): Hypothesis testing tells us _______
The probability of obtaining this data, given the null hypothesis is true
Stats (1): Cohen's D or r refers to an estimate of ....
Effect size
Stats(1): What percent of scores fall between -1 standard deviation and +1 standard deviation?
68%
What are two factors that influence power (ex: how increase power)?
Increasing alpha, decreasing beta
Stats (1): Limitation of hypothesis testing
"data mining"- researching change alpha to make their findings signficant
Groups: Which is the best example of a multi-level analysis?
Studying how a norm influences the group as a whole as well as each member.
Groups: Which is NOT one of the key characteristics of a group/team? (sample knockout question)
A leader
Groups: I believe that a team is, in many respects, like a complex organism in that it takes in inputs from the environment, processes those inputs, and then generates outcomes and outputs in a continuous, recursive process. I am a(n) ---- theorist in my approach to teams.
Systems
Groups: I have substantial ---- because I am linked to many individuals and groups through an extensive network of interpersonal relationships
Social capital
Groups: Which one is NOT consistent with a systems theory of teams?
The elements are sequentially invariant: inputs lead to processes which lead to outputs.
Groups: True or false, Individualists actively avoid disagreement and dissent within the group.
False
Groups: Steiner’s “law” of group productivity assumes that you must take into account ---- to predict a group’s actual performance level.
Losses due to faulty process
Groups: I’m confused. As group leader, some people think I should maintain strict control, while others feel that I should say as little as possible. I’m experiencing
Intrarole conflict
Groups: After the surgery the medical team sits over coffee, discussing the case, and identifying ways to perform the next surgery even more effectively my making modifications to their working procedures. Marks, Mathieu, and Zaccaro would label this meeting part of the team’s ---- processing.
transition
Groups: Jeni studies reactions to exclusion by having people imagine they cheated on a test and then indicating how they would feel about themselves in such a situation and the extent to which they would risk exclusion by undertaking such an act. Hers was a(n) ---- study.
correlational
Groups: ---- norms describe what people do; ---- norms state what people should do.
Descriptive; injunctive
Groups: True or false, groupthink does not occur in noncohesive groups
True (although questionable)
Groups: Given the relationship between network position and satisfaction, the majority of the group members will be more satisfied when working in a ---- network.
decentralized
Groups: If you are a high status person in a hierarchically organized group, most likely----
You will initiate more communications than a low status person.
Groups: True or false, In some cases, groups are more effective if they ignore conflicts and concentrate instead on the work to be done
True
Groups: Lewin’s “law” argued that people are most easily influenced
When they are part of a group that changes
Groups: I am an excellent speaker, who through judicious phrasings and careful delivery of facts can often change people’s opinions. I have ---- power.
informational
Groups: Which is the key to determining when social facilitation AND social loafing will or will not occur?
evaluation apprehension
Groups: True or false, Not all groups require a leader.
True
Groups: True or false, The presence of others speeds up the performance of simple, well-learned tasks.
True
Stress: Job-Demands Resources Theory
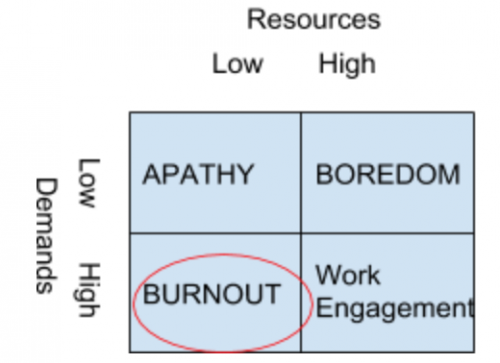
Stress: Conservation of Resources (COR)
Obtain and protect things we value (resources)
Resource loss or threat of loss creates stress
Failure to replenish resources used
Stress: Person-Environment Fit Model
Stress arises from misfit between person and environment
Demands vs abilities
and Needs vs supplies/values
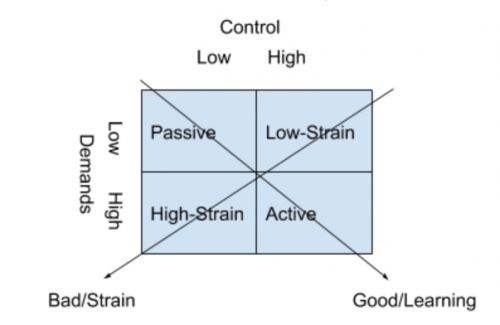
Stress: Karasek’s Demand-Control Model
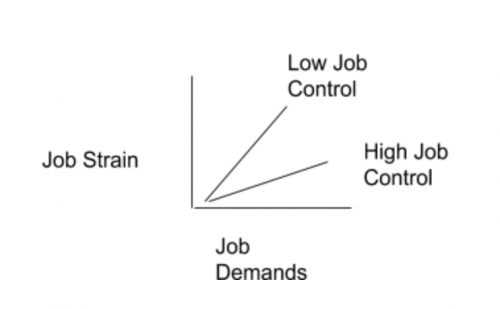
Stress: Buffer hypothesis
Stress: Primary and secondary appraisal
Primary appraisal: Is situation stressful? - Harm, Threat, Challenge
Secondary appraisal: What do I do next? - Resources, Coping
Stress: 4 Basic Dimensions To Measure The Stress Response
self-report, behavioral, physiological, biochemical
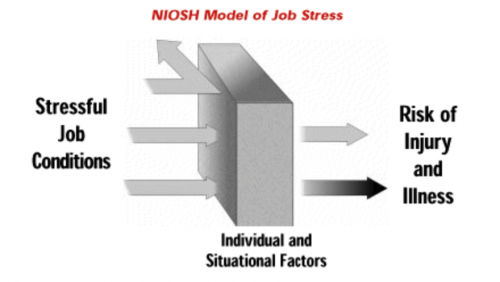
Stress: Niosh model of stress
Stress: types of role conflict
intrarole (in your single role), interrole (between your many roles in life), person-role (when behaviors for role are incongruent with the basic values, attitudes, or preferences of the person)
Stress: Surface acting and deep acting
Surface acting
Faking emotions to meet org goals and requirements
Deep acting
Adjusting emotions to meet org goals and requirements
Cognitive reappraisal: changing perception of situation (if it were me I would be mad, too)
Attention deployment: thinking of situations that induce required emotion
Surface acting is related to incivility, deep acting unrelated to inciv
Stress: Display rules
Emotion regulation norms to suppress negative and express positive
Explicit: policies telling you how to treat customers
Implicit: climate that emphasizes teamwork
Stress: levels of interventions
Primary Prevention- Directed at Stressor, Secondary Prevention- Directed at Response, Tertiary Prevention- Directed at Symptoms
Stress: Organizational Interventions
Modifying Task and Physical Demands
Modifying Role and Interpersonal Demands
Stress: Coping strategies, Problem focused vs Emotion focused
PF: Deal with demands of SE (stressful event), EF: Deal with emotional disturbance of SE
Selection: If we have a test called “x” and rxx=.80, this means…
20% of the differences in test scores is due to error and 80% is due to true variance
Selection: Expectancy tables and calculations

Selection: The purpose of cross-validation is to
Indicate whether a measure is still predictive in a different sample
Selection: Types of validity, chart

Selection: According to your book, ___ performance measures are best used for research purposes, and ____ performance measures are best used for selection purposes.
Multiple; composite
Selection: Which two methods of combining predictor information are generally considered the best?
Pure statistical and mechanical composite
Selection: Which of the following is NOT an assumption of the multiple regression selection decision-making model?
A minimum amount of each KSA is necessary for successful job performance
Selection: What does “unit weighting” refer to?
When you equally weight all predictors
Selection: Which selection decision-making model is most appropriate to use when physical abilities are essential to job performance?
Multiple cutoffs
Selection: Which of the following is typically NOT a consideration when evaluating the adequacy of a predictor?
Raw scores
Selection: “Qualified individual with a disability” refers to which of the following?
Individuals with a disability who, with or without reasonable accommodation, can perform the essential functions of the job
Selection: What are the three options an employer has for defense in an adverse impact discrimination case?
Business necessity, BFOQ, validity
Selection: Which of the following criteria can be used for framing a BFOQ?
Gender. (NOT race or color)
Selection: The text talked about “keying” items in biodata. What does this mean?
Identifying one or more “acceptable” answers to each question, usually by correlating options with performance measures
Selection: Reference checks only demonstrate a validity of rxy=.18. Why is this so low?
Interrater reliability is often quite low
Selection: Which of the following is NOT part of how to structure an interview?
Use a paired comparison methodology to rank applicants
Selection: Core self-evaluations consists of what four traits?
Self-esteem, generalized self-efficacy, locus of control, and emotional stability
Selection: Which of the following tests has similar validity to that of cognitive ability?
Work samples
Selection: Research on validity generalization for cognitive ability suggests that cognitive ability:
Generalizes both within and across jobs
Selection: According to the table in your book, which test should we use along with a cognitive ability test if we want to maximize incremental validity?
Integrity test
Selection: The black-white d-value for cognitive ability test scores is approximately:
1.00
Selection: In terms of physical ability tests, male-female differences tend to be smallest for:
Movement quality
Selection: Which of the following statements best describes the racial differences we observe on cognitive ability tests?
The regression line for different races has the same slope and intercept, but races have different mean scores on the measure
Selection: Which type of performance tends to show the largest subgroup difference?
Task performance
Selection: Which of the following is a shortcoming of situational judgement tests (SJTs)?
They are expensive and difficult to design
Selection: Which of the following is a valid criticism of assessment centers?
They demonstrate a lack of construct validity
Selection: The situation a participant is provided in an SJT is known as a(n):
Item stem
Selection: SJTs are considered to be (low or high fidelity)
low fidelity
Selection: conducting a concurrent validity study, why might validity be lower than we expect? What could we do?
low reliability, restricted range. you could try correcting for attenuation (looking at it as if we have perfect reliability) or try running predictive study
Selection: we want to do a validation study but we have only a few employees and there is little turnover. Ideas?
validity generalization, Examine content validity using SMEs and Incumbents (interviews), concurrent validity (but you probably need more people for this)
Stress: sympathetic and parasympathetic = ?
Sympathetic: fight or flight, parasympathetic: rest and digest
Training: _____ analysis involves determining the appropriateness of training, given the company’s business strategy, its resources available for training, and support by managers and peers.
Organizational
Training: _____analysis involves determining whether performance deficiencies result from lack of knowledge or skills
person
Training: One of the best ways to establish and increase individuals’ self-efficacy is to
Provide them with a training program that allows them to succeed early in the training
Training: The type of job analysis most often used to determine training needs is
task-oriented
Training: As an individual difference, goal orientation is (state or trait)
both/either depending on environment
Training: Person level needs analysis...
Focuses on identifying who needs training and whether employees are ready for training
Training: The first step in the strategic training and development process is...
Identify the business strategy and org goals
Training: Ashley is conducting an organizational analysis for the BMH company and finds that the company's’ long term goal of being ranked as number one in pet food sales is not being reached. Ashley’s organizational analysis should also consider:
The culture of training and development in the organization
Training: Which of the following steps of the training design process involves person and task analysis
Conducting needs assessment
Training: Which of the following statements is true of needs assessment?
The role of the needs assessment is to determine if training is the appropriate solution
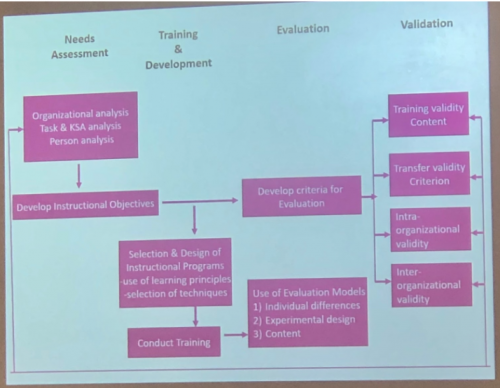
Training: ISD Model (instructional systems design)
OD: Appreciative Inquiry
Positive,
4 stages of AI -
Discovery
Dream
Design
Destiny
OD: Balanced Scorecard
Used to prove the effectiveness of OD efforts
Comprehensive framework that translates a company's strategic objectives into performance measures
Measure of financial growth, performance, internal processes and innovation/development
OD: Bethel NTL
National Training Laboratories founded by Kurt Lewin in Bethel
ab Training/T-groups - small, unstructured group in which participants learn from their own interactions and evolving group processes about such issues as interpersonal relations, personal growth, leadership and group dynamics
OD: Edward Deming/Total Quality Management
a system of management based on the principle that every staff member must be committed to maintaining high standards of work in every aspect of a company's operations.
OD: Equifinality
in open systems a given end state can be reached by many potential means
OD: The Fifth Discipline
The five disciplines of learning organizations are -
Building a shared vision
Systems thinking
Mental models
Team Learning
Personal mastery
OD: Functional Organizations
Most widely used organizational structure
Dividing organization into functional units
OD: Grid OD
Six phase program lasting about 3-5 years.
OD: Tavistock Institutude
The Tavistock Institute of Human Relations or TIHR is a British not-for-profit organisation which applies social science to contemporary issues and problems.
OD: Tragedy of the Commons
People only think of themselves and then ruin it for everyone. , too much demand for supply
OD: Visioning activities
A process typically initiated by key executives to define the mission of the organization and to clarify desired values for the organization, including valued outcomes and valued organizational conditions
Motivation: Lawler's Model of Satisfaction
Lawler's Model → if you want to measure satisfaction with pay, you don't just ask how much money you get, but also how much you expect to receive
Satisfaction = f(amount received - amount expected)
Motivation: Bandura's Efficacy Model
Motivation = f(efficacy)
Motivation to perform is a function of whether you believe you can perform; motivated to perform behavior to the extent that we believe we can
Something occurs cognitively that guides behavior
Social learning theory = learn through observation of others
Motivation: MBO
Mutually set goals (manager and subordinate develop goals together)
Goals used for development and growth
Motivation: Berlyne's Theory
Inverted U Theory:
--Moderate levels of arousal are naturally pleasurable
--Avoid low levels of arousal (low pleasure) -- boredom
--Avoid high levels of arousal (uncomfortable) -- anxiety
Stimuli that produce arousal:
--Any stimuli that is different than what's expected
--Any stimuli with collative qualities (novel, surprising, conflict, uncertainty)
Motivation: Cognitive Evaluation Theory (Deci & Ryan)
Activity may be intrinsically motivating, but once a reward is attached to the activity, interest in the activity decreases
Components of CET:
--Sense of competence derived from activity -feeling competent increases intrinsic motivation
--Self-determination (rewards hinder this) -increases intrinsic motivation
--Rewards take the autonomy out of the activity -they ruin intrinsic motivation
Rewards that hinder intrinsic motivation:
--Expected rewards
--Salient (obvious) rewards
--Non-performance based rewards
--Piece-rate pay, salary, bonuses
Motivation: Conjunctive vs. Independent Accumulation
Conjunctive Goals
--Success = consecutive days
Independent Goals
--Success = total days
Motivation: Self-Serving Attribution Bias
Take credit for success (effort, ability)
Blame environment for failures (task difficulty, luck)
Stress: Physio responses
Cardiovascular = most common. Heart rate, BP, other (cardiovascular reactivity, blood cholesterol). But this is affected by genetics, demographics (sex, race, age), pre-existing health conditions, environment, etc. (hot in the room, caffeine, alcohol, nicotine, meds). It is very hard to control for all of these things.
Blood cholesterol- Seasonal factors. Lower in fall and winter, higher in spring and summer.
Epinephrine- affected health conditions, sex
Cortisol - Can be measured in blood, urine, or saliva. More responsive to chronic than acute stressors, timing is crucial, strong time of day effects
Stress: 4 Basic Dimensions To Measure The Stress Response
Physiological
Biochemical
Behavioral
Self-report